



Let’s try an experiment - taking many of the things I’ve been blogging about over the past few years and applying them to the design and build of an actual application, with the source code published step by step.
Several years ago, I created WordTutor, an interactive spelling tutor for my daughter that used speech synthesis to read out the words for her to spell.
Why do this now?
I was never particularly happy with the underlying source code - and it was never particularly successful as a commercial product. The opportunity to rewrite it from scratch, as an open source project that anyone can play around with, seems to be a good one.
Architecture
Any project needs to start with a few architectural decisions:
- Targeting the latest version .NET Core (currently 2.2, but moving to 3.0 when released), and using .NET Standard for as much as possible, to allow cross platform code reuse.
- Using the latest version of C# (currently version 7.3 but we’ll move to 8.0 as soon as it is formally released).
- Unit tested with high coverage (but not 100% because that’s a fools errand) using xUnit, Fluent Assertions and anything else that seems relevant.
- With WPF moving to open source model, we’ll try to use that (along with .NET Core 3.0) for the user interface.
- Model-View-ViewModel (MVVM) architecture for the application.
- Redux style (immutable application state) but with an idiomatic .NET twist.
I’m sure more will come up as we go along.
Redux Model
One good place to start is with the application model itself. Redux is both a JavaScript framework and a design pattern for managing application state. The key idea is to handle the entire state of the application as an immutable object that is modified only in predictable ways.
We’ll explore how this works later on in this series - but first we need at least an initial guess for how our application state will be represented. Here’s a quick class diagram:
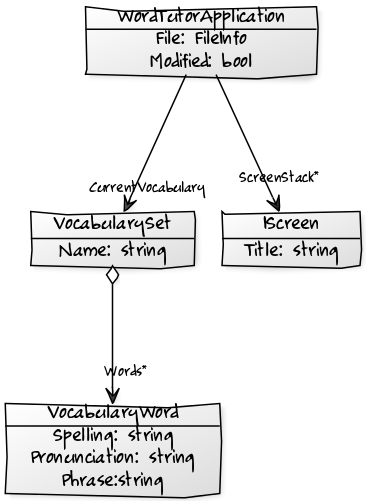
At the bottom of the heirarchy, we find VocabularyWord, representing a single word that needs to be learned. We have the correct spelling of the word, a sample phrase (to put the word in context for our user), and a pronunciation guide. This guide is what we feed to our vocaliser when the word is spoken in isolation. When developing the original WordTutor, I found that this was necessary to work around some odd choices by the speed synthesizer in Windows 7. I’m predicting we’ll still need it on newer platforms.
A collection of words is a VocabularySet. At the moment, the only property is a name, so that we can tell different word lists apart.
The root of the model is the WordTutorApplication class. This has a reference to our CurrentVocabulary as well as a couple of properties used for change tracking.
Lastly, the interface IScreen is used to create a stack of screens that will allow us to interact with the user. These screens will form a state machine, with the changes between screens forming the edges of the state transition diagram.
Next time
In the next post, we’ll start our implementation of the application model with VocabularyWord.
Comments
blog comments powered by Disqus